I graduated from the Computer Science Department at the University of California, Los Angeles in 2019. During my Ph.D. study I did computer vision research in the Center for Vision, Cognition, Learning, and Autonomy advised by Professor Song-Chun Zhu.
I am currently working at Google. Please refer to my Google Scholar page for a more up-to-date publication list.
My research interests include Computer Vision, Machine Learning, and Cognitive Science.
We who cut mere stones must always be envisioning cathedrals.
Cooperative Holistic 3D Scene Understanding from a Single RGB Image.
[paper] [supplementary]
Conference Machine Learning Computer Vision
Generalized Earley Parser: Bridging Symbolic Grammars and Sequence Data for Future Prediction.
[paper] [supplementary] [code]
Conference Machine Learning Computer Vision
Human-centric Indoor Scene Synthesis Using Stochastic Grammar.
[paper] [supplementary] [code] [project]
Conference Computer Vision Computer Graphics
[Invited talk] I presented our work on "Examining Human Physical Judgments Across Virtual Gravity Fields" in VRLA 2017.
Invited Talk Virtual Reality Cognitive Science
[Oral] The Martian: Examining Human Physical Judgments Across Virtual Gravity Fields.
Accepted to TVCG
Oral Journal Virtual Reality Cognitive Science

This project aims to predict future human activities from partially observed RGB-D videos. Human activity prediction is generally difficult due to its non-Markovian property and the rich context between human and environments. We use a stochastic grammar model to capture the compositional/hierarchical structure of events, integrating human actions, objects, and their affordances.
Computer Vision Robotics
This project studies how to realistically synthesis indoor scene layouts using stochastic grammar. We present a novel human-centric method to sample 3D room layouts and synthesis photo-realistic images using physics-based rendering. We use object affordance and human activity planning to model indoor scenes, which contains functional grouping relations and supporting relations between furniture and objects. An attributed spatial And-Or graph (S-AOG) is proposed to model indoor scenes. The S-AOG is a stochastic context sensitive grammar, in which the terminal nodes are object entities including room, furniture and supported objects.
Computer Vision Computer Graphics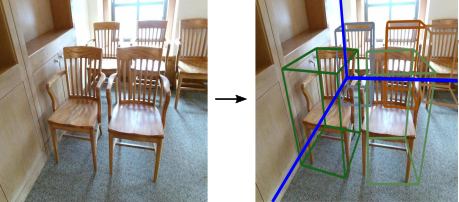
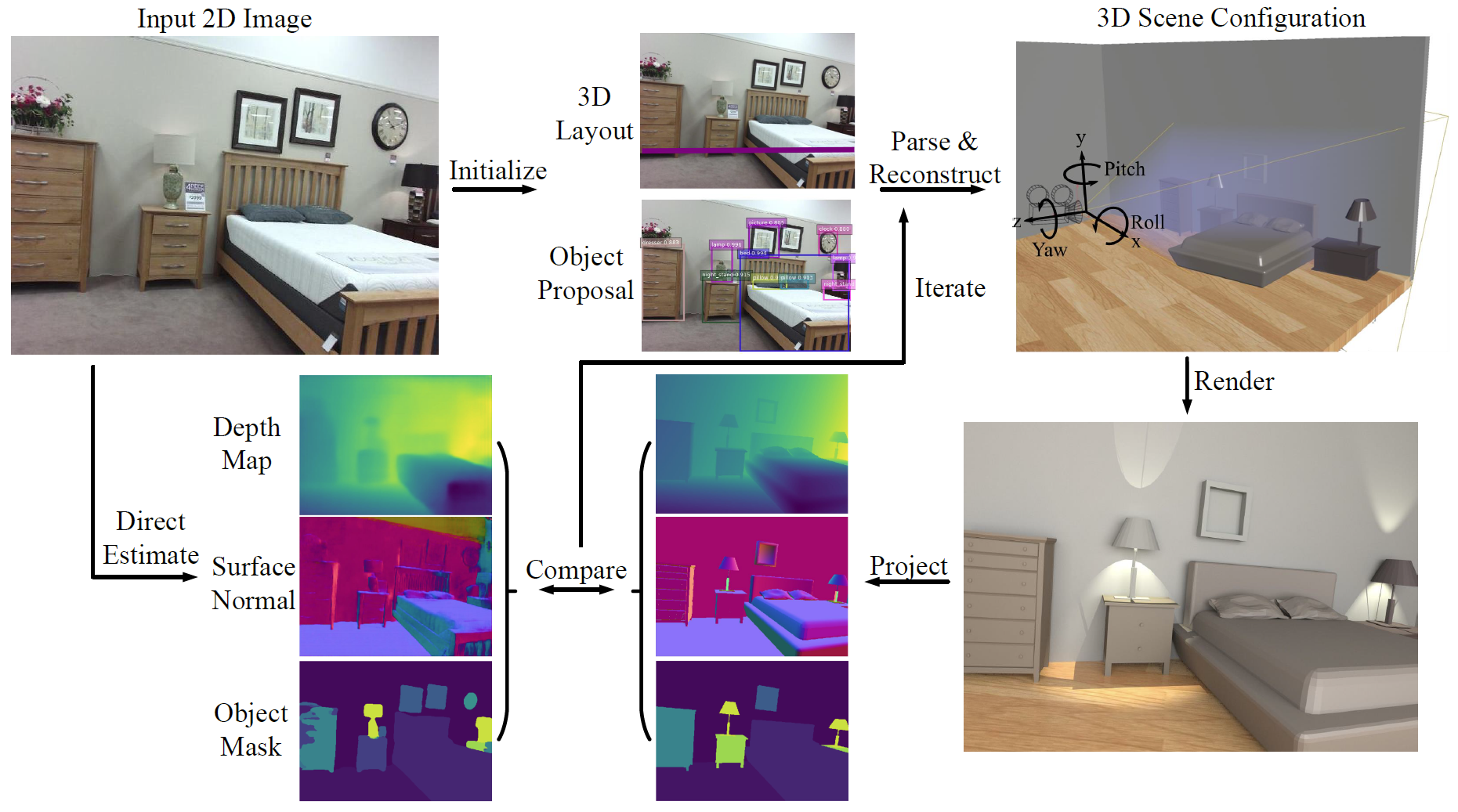
Siyuan Huang, Siyuan Qi, Yinxue Xiao, Yixin Zhu, Ying Nian Wu, Song-Chun Zhu.
neurips 2018, Montreal, Canada
Conference Machine Learning Computer Vision
@inproceedings{huang2018cooperative,
title={Cooperative Holistic Scene Understanding: Unifying
3D Object, Layout, and Camera Pose Estimation},
author={Huang, Siyuan and Qi, Siyuan and Xiao, Yinxue and Zhu, Yixin and Wu, Ying Nian and Zhu, Song-Chun},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2018}
}
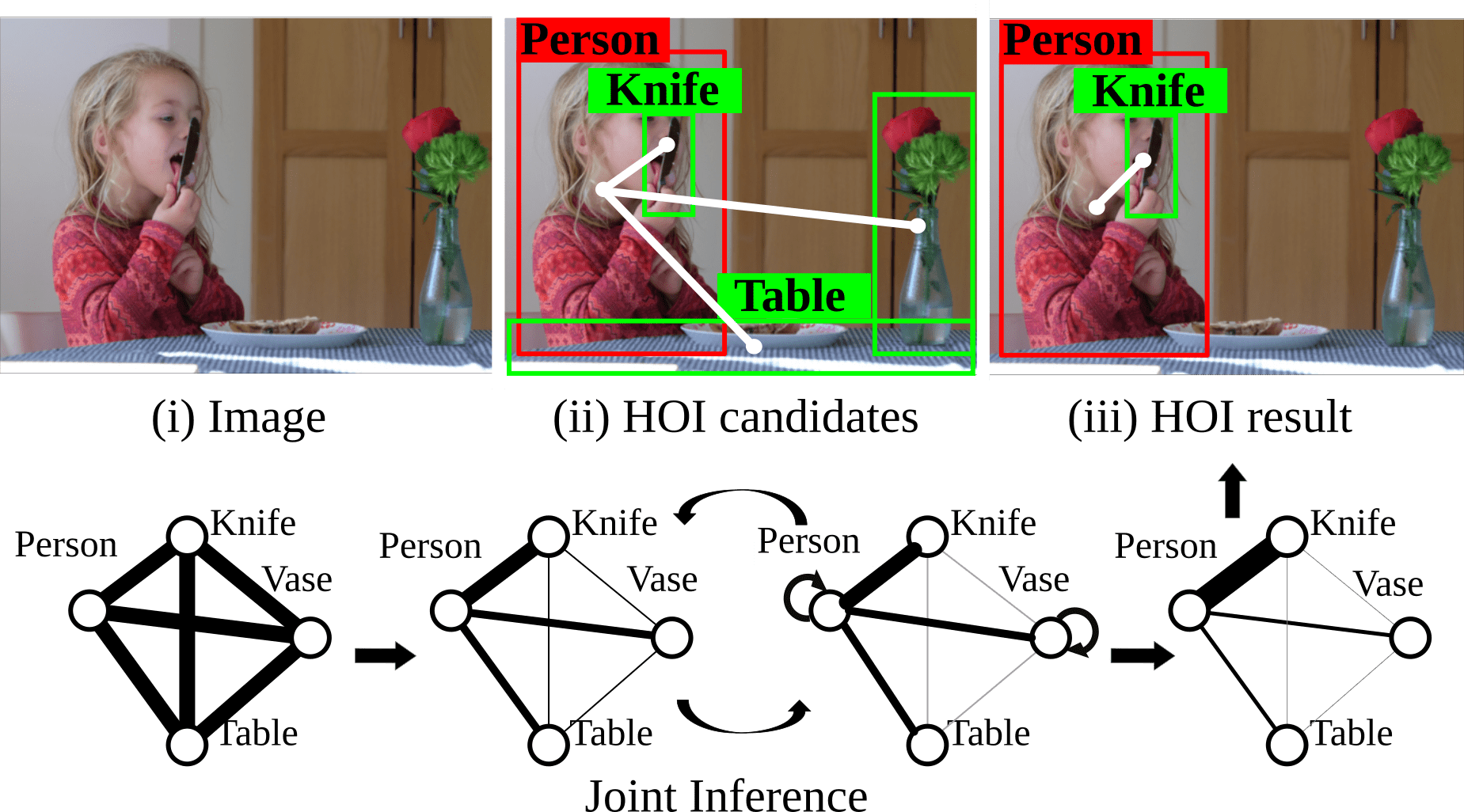
Siyuan Qi*, Wenguan Wang*, Baoxiong Jia, Jianbing Shen, Song-Chun Zhu.
ECCV 2018, Munich, Germany
Conference Computer Vision
@inproceedings{qi2018learning,
title={Learning Human-Object Interactions by Graph Parsing Neural Networks},
author={Qi, Siyuan and Wang, Wenguan and Jia, Baoxiong and Shen, Jianbing and Zhu, Song-Chun},
booktitle={European Conference on Computer Vision (ECCV)},
year={2018}
}
Siyuan Huang, Siyuan Qi, Yixin Zhu, Yinxue Xiao, Yuanlu Xu, Song-Chun Zhu.
ECCV 2018, Munich, Germany
Conference Computer Vision
@inproceedings{huang2018holistic,
title={Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image},
author={Huang, Siyuan and Qi, Siyuan and Zhu, Yixin and Xiao, Yinxue and Xu, Yuanlu and Zhu, Song-Chun},
booktitle={European Conference on Computer Vision (ECCV)},
year={2018}
}
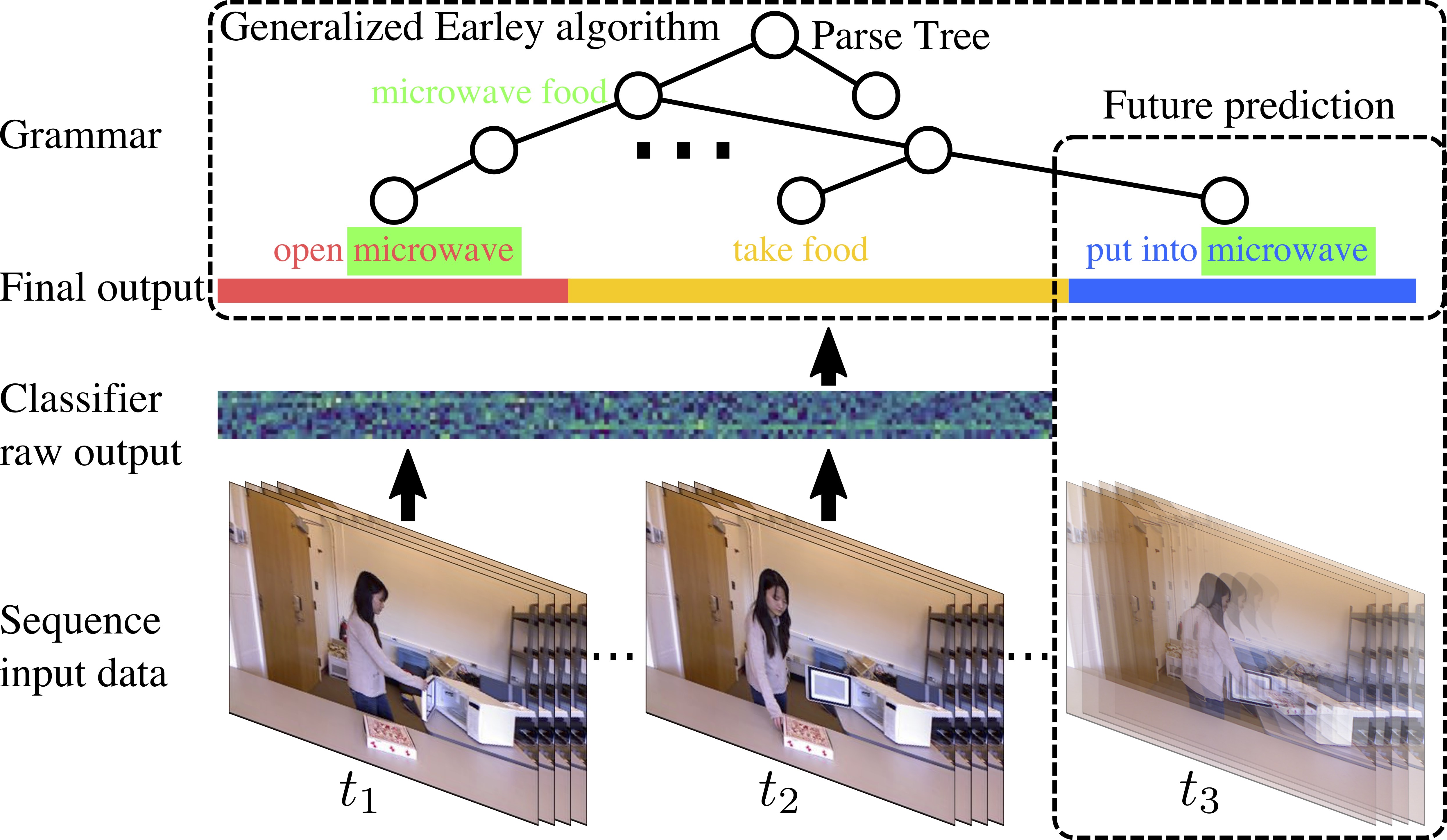
Siyuan Qi, Baoxiong Jia, Song-Chun Zhu.
ICML 2018, Stockholm, Sweden
Conference Machine Learning Computer Vision
@inproceedings{qi2018generalized,
title={Generalized Earley Parser: Bridging Symbolic Grammars and Sequence Data for Future Prediction},
author={Qi, Siyuan and Jia, Baoxiong and Zhu, Song-Chun},
booktitle={International Conference on Machine Learning (ICML)},
year={2018}
}

Chenfanfu Jiang*, Siyuan Qi*, Yixin Zhu*, Siyuan Huang*, Jenny Lin, Lap-Fai Yu, Demetri Terzopoulos, Song-Chun Zhu.
IJCV 2018
Journal Computer Vision Computer Graphics
@article{jiang2018configurable,
title={Configurable 3D Scene Synthesis and 2D Image Rendering with Per-Pixel Ground Truth Using Stochastic Grammars},
author={Jiang, Chenfanfu and Qi, Siyuan and Zhu, Yixin and Huang, Siyuan and Lin, Jenny and Yu, Lap-Fai and Terzopoulos, Demetri, Zhu, Song-Chun},
journal = {International Journal of Computer Vision (IJCV)},
year={2018}
}

Siyuan Qi, Yixin Zhu, Siyuan Huang, Chenfanfu Jiang, Song-Chun Zhu.
CVPR 2018, Salt Lake City, USA
Conference Computer Vision Computer Graphics
@inproceedings{qi2018human,
title={Human-centric Indoor Scene Synthesis Using Stochastic Grammar},
author={Qi, Siyuan and Zhu, Yixin and Huang, Siyuan and Jiang, Chenfanfu and Zhu, Song-Chun},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018}
}

Siyuan Qi, Song-Chun Zhu.
ICRA 2018, Brisbane, Australia
Conference Reinforcement Learning Robotics
@inproceedings{qi2018intent,
title={Intent-aware Multi-agent Reinforcement Learning},
author={Qi, Siyuan and Zhu, Song-Chun},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2018}
}

Xu Xie, Hangxin Liu, Mark Edmonds, Feng Gao, Siyuan Qi, Yixin Zhu, Brandon Rothrock, Song-Chun Zhu
ICRA 2018, Brisbane, Australia
Conference Robotics
@inproceedings{xu2018unsupervised,
title={Unsupervised Learning of Hierarchical Models for Hand-Object Interactions},
author={Xie, Xu and Liu, Hangxin and Edmonds, Mark and Gao, Feng and Qi, Siyuan and Zhu, Yixin and Rothrock, Brandon and Zhu, Song-Chun},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2018}
}

Siyuan Qi, Siyuan Huang, Ping Wei, Song-Chun Zhu.
ICCV 2017, Venice, Italy
Conference Computer Vision
@inproceedings{qi2017predicting,
title={Predicting Human Activities Using Stochastic Grammar},
author={Qi, Siyuan and Huang, Siyuan and Wei, Ping and Zhu, Song-Chun},
booktitle={International Conference on Computer Vision (ICCV)},
year={2017}
}

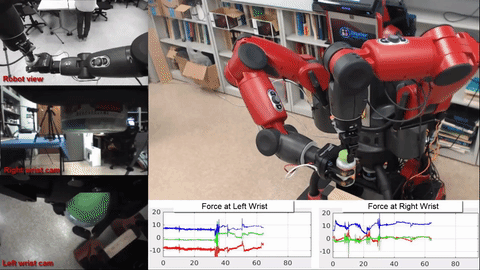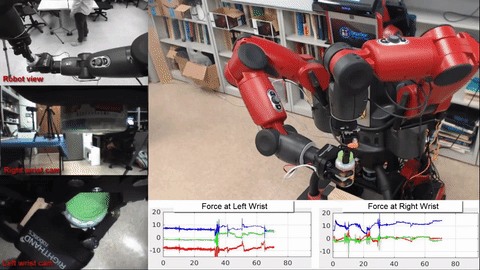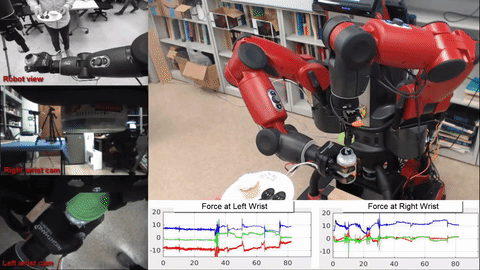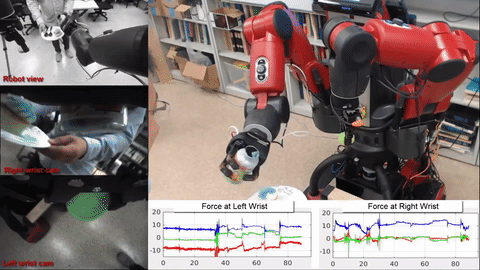
Mark Edmonds*, Feng Gao*, Xu Xie, Hangxin Liu, Siyuan Qi, Yixin Zhu, Brandon Rothrock, Song-Chun Zhu.
IROS 2017, Vancouver, Canada
Oral Conference Robotics
@inproceedings{edmonds2017feeling,
title={Feeling the Force: Integrating Force and Pose for Fluent Discovery through Imitation Learning to Open Medicine Bottles },
author={Edmonds, Mark and Gao, Feng and Xie, Xu and Liu, Hangxin and Qi, Siyuan and Zhu, Yixin and Rothrock, Brandon and Zhu, Song-Chun},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2017}
}

Tian Ye, Siyuan Qi, James Kubricht, Yixin Zhu, Hongjing Lu, Song-Chun Zhu.
IEEE VR 2017, Los Angeles, California, USA
Accepted to TVCG
@article{ye2017martian,
title={The Martian: Examining Human Physical Judgments across Virtual Gravity Fields},
author={Ye, Tian and Qi, Siyuan and Kubricht, James and Zhu, Yixin and Lu, Hongjing and Zhu, Song-Chun},
journal={IEEE Transactions on Visualization and Computer Graphics},
volume={23},
number={4},
pages={1399--1408},
year={2017},
publisher={IEEE}
}